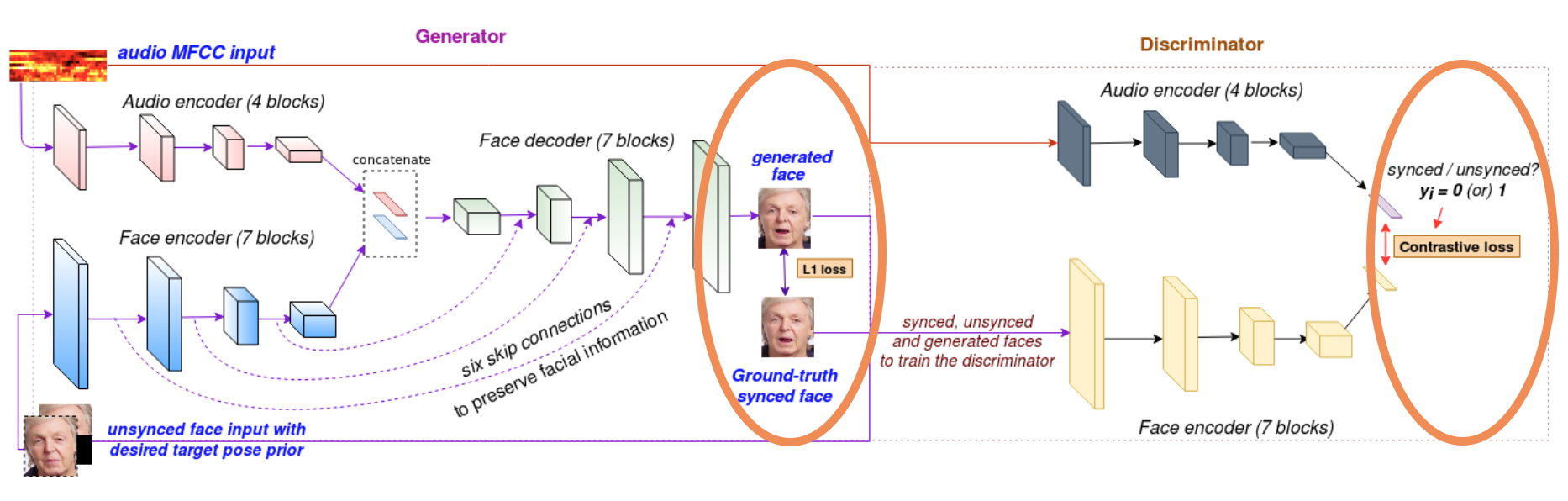
We explore the problem of lip-syncing a talking face video to match the target speech segment to the lip and facial expression of the person in the video. The primary task is to achieve accurate audio-video
synchronization given a person’s face and target audio clip, where videos feature faces are dynamic and unconstrained.
This technique is broadly applicable to many scenarios such as realistic dubbing in the movie industry, conversational agents, virtual anchors, and gaming. Providing a natural lip movement and facial expression generation improves the user’s experience in these applications.
Despite the recent advances and its wide applicability, synthesizing a clear, accurate, and human-like performanceis still a challenging task. We are exploring the limitations of the state-of-the-art techniques and propose possible solutions.
We have noticed that lip-sync generation has spuriousmovements on non-lip region, like lower chin or side chin as shown below (right video). We have observed this when the face detection fails to correctly localize the lip region. Profile view of the detected face usually faces this limitation. We need to observe few more such cases to generalize the limitation and come up with a possible modification.
Fig.2 From left to right: (a) LipGAN generates reasonably accurate lip sync (b) LipGAN generates spurious lip sync on non-lip region
Teeth Region Deformation
We observed that the LipGAN model generates image frames which smoothed out teeth and lip region. Lower teeth is merged with upper lip and smoothed out.
Fig.3 From left to right: (a) LipGAN generates reasonably accurate lip sync (b) LipGAN generates frames with merged (smoothed) teeth and upper lip region
Ongoing Progress
We are trying to modify the face reconstruction loss module. Currently, the face reconstruction loss is calculated for the whole image to ensure correct pose generation, background around the face, and preservation of the identity. The lip region contributes to less than 4% of the total reconstruction loss. However, we need to emphasize the reconstruction loss in lip region. We are planning to explore different techniques, like weighted reconstruction loss, or having a separate discriminator (as in a multi-task setting) to focus on the lip-sync only. We can jointly train the GAN framework with two discriminator networks (one for visual quality, and one for lip sync). Additionally, We will manually evaluate and judge the lip-synchronization based on performance metrics discussed in previous works.
Optional Goal
If time and computational power permit, we can experiment with different model architectures for each of the blocks shown in the LipGAN architecture. For example, we can use state-of-the-art model architectures to extract richer and complex audio and face embedding.