LipGAN: Speech to Lip Sync Generation
Proposal (PDF)
Motivation
In this course project, we explore the problem of lip-syncing a talking face video to match the target speech segment to the lip and facial expression of the person in the video. The primary task is to achieve accurate audio-video synchronisation given a person's face and target audio clip. We can extend it to be speaker-independent model to produce lip-sync in the ''wild'', where videos feature faces that are dynamic and unconstrained.
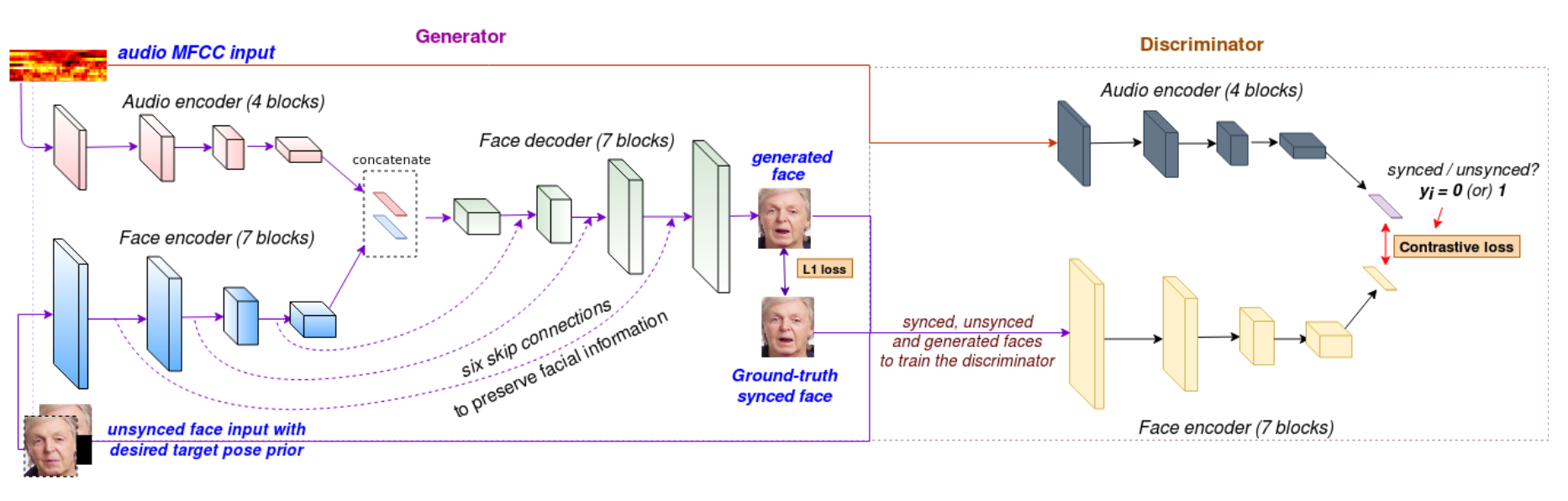
State-of-the-art Model

Time Table
| Time | Work |
|---|---|
| Till Feb 24: | Come up with a project proposal document and create web page. Discussion about possible techniques and directions to be explored. |
| Feb 25 - Mar 07 | Set up the running environment for the state-of-the-art methods. Start implementing an existing approach as a baseline. |
| Mar 08 - Mar 20 | Have one working implementation of an existing approach (LipGAN). |
| Mar 21 - Mar 24 | Write Mid-term report. |
| Mar 25 - Apr 11 | Try experimenting with different loss formulations, multi-task framework. Explore alternate methods available in literature. |
| Apr 12 - Apr 23 | Summarize result and ablation studies. Complete all experiments. |
| Apr 25 - May 5 | Complete course project web page. |