|
I graduated with M.S. in Computer Sciences from University of Wisconsin-Madison (UWM/UWisc). My research interests lie primarily in Deep Learning and its application to Computer Vision, Natural Language Processing and recommendation systems. Over the years, I have gained strong academic background, relevant work experience, and research aptitude (17+ publications, 505+ citations, h-index: 10, i-10 index: 10).
Google Scholar / LinkedIn / Wisc email / Gmail / Social medial links |
 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Citations a/c to Google Scholar: (17+ publications, 505+ citations, h-index: 10, i-10 index: 10). |
|
|
|
|
|
|
|
Problem Statement: "Given a user query and candidate passages corresponding to each, the task is to mark the most relevant passage which contains the answer to the user query. As search engines evolve to respond to speech inputs and as usage of ambient devices like speakers grow in the society etc. returning 10 blue links to a search query is not always desirable. At Bing.com, our aim is to serve answer to questions directly without users having to search through the 10 blue links."
|
|
|
|
For the most up-to-date list of publications, please refer to Google Scholar Profile.
|
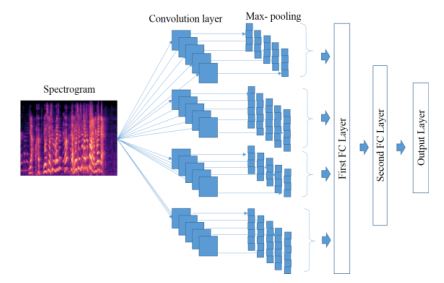
|
This paper proposes a speech emotion recognition method based on phoneme sequence and spectrogram. Both phoneme sequence and spectrogram retain emotion contents of speech which is missed if the speech is converted into text. We performed various experiments with different kinds of deep neural networks with phoneme and spectrogram as inputs. Three of those network architectures are presented here that helped to achieve better accuracy when compared to the state-of-the-art methods on benchmark dataset. A phoneme and spectrogram combined CNN model proved to be most accurate in recognizing emotions on IEMOCAP data. We achieved more than 4% increase in overall accuracy and average class accuracy as compared to the existing state-of-the-art methods.
|
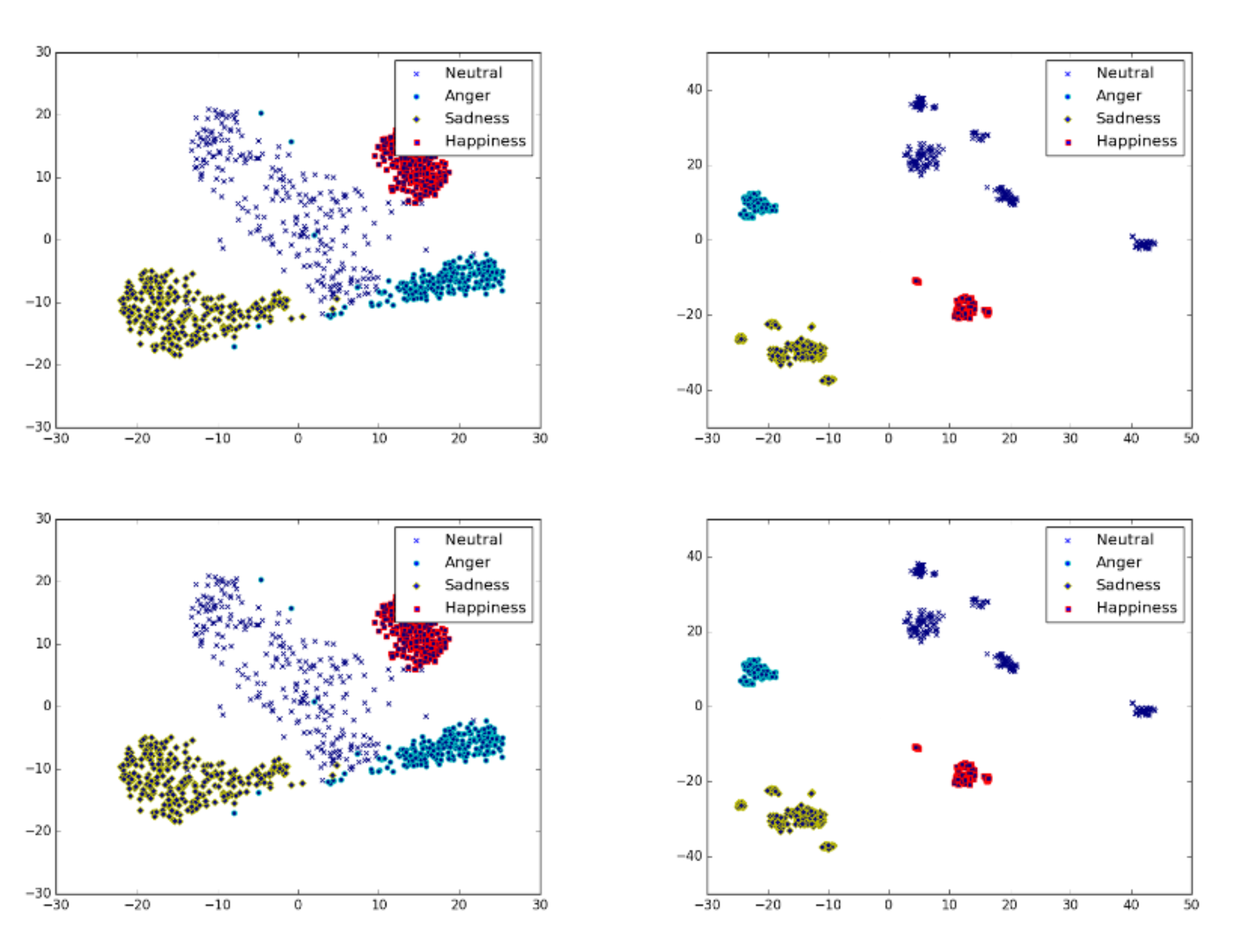
|
This paper proposes a Convolutional Neural Network (CNN) inspired by Multitask Learning (MTL) and based on speech features trained under the joint supervision of softmax loss and center loss, a powerful metric learning strategy, for the recognition of emotion in speech. Speech features such as Spectrograms and Mel-frequency Cepstral Coefficient s (MFCCs) help retain emotion-related low-level characteristics in speech. We experimented with several Deep Neural Network (DNN) architectures that take in speech features as input and trained them under both softmax and center loss, which resulted in highly discriminative features ideal for Speech Emotion Recognition (SER). Our networks also employ a regularizing effect by simultaneously performing the auxiliary task of reconstructing the input speech features. This sharing of representations among related tasks enables our network to better generalize the original task of SER. Some of our proposed networks contain far fewer parameters when compared to state-of-the-art architectures.
|
|
In this paper, a hybrid MD-kNN method for real time sensor node tracking is proposed. The method combines two individual location hypothesis functions obtained from generalized maximum depth and generalized kNN methods. The individual location hypothesis functions are themselves obtained from multiple sensors measuring visible light, humidity, temperature, acoustics, and link quality. The hybrid MD-kNN method therefore combines the lower computational power of maximum depth and outlier rejection ability of kNN method to realize a robust real time localization method. Additionally, this method does not require the assumption of an underlying distribution under non-line-of-sight (NLOS) conditions. Additional novelty of this method is the utilization of multivariate data obtained from multiple sensors which has hitherto not been used. The affine invariance property of the hybrid MD-kNN method is proved and its robustness is illustrated in the context of node localization. Experimental results on the Intel Berkeley research data set indicates reasonable improvements over conventional methods available in literature.
|
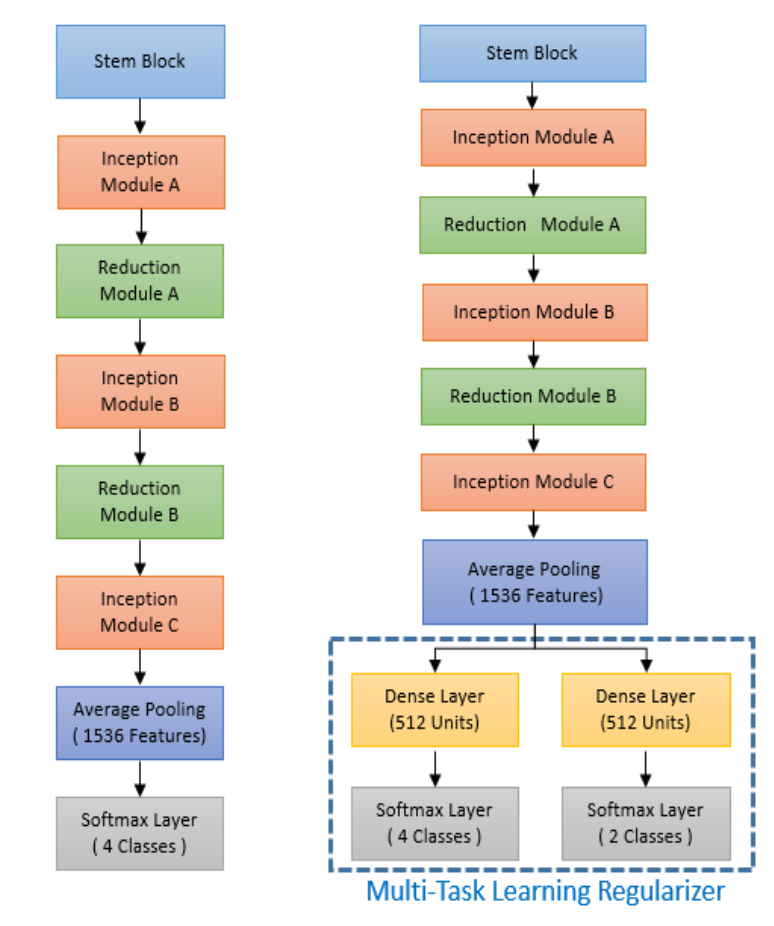
|
This research proposes a Deep Neural Network architecture for Speech Emotion Recognition called Emoception, which takes inspiration from Inception modules. The network takes speech features like Mel-Frequency Spectral Coefficients (MFSC) or Mel-Frequency Cepstral Coefficients (MFCC) as input and recognizes the relevant emotion in the speech. We use USC-IEMOCAP dataset for training but the limited amount of training data and large depth of the network makes the network prone to overfitting, reducing validation accuracy. The Emoception network overcomes this problem by extending in width without increase in computational cost. We also employ a powerful regularization technique, Multi-Task Learning (MTL) to make the network robust. The model using MFSC input with MTL increases the accuracy by 1.6% vis-à-vis Emoception without MTL. We report an overall accuracy improvement of around 4.6% compared to the existing state-of-art methods for four emotion classes on IEMOCAP dataset.
|
|
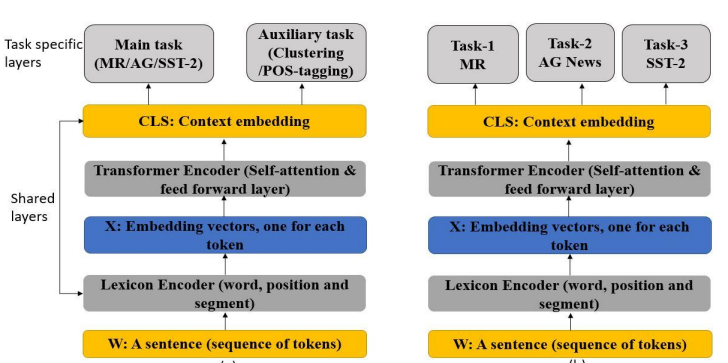
We propose a multi-task learning-based framework for natural language understanding tasks like sentiment and topic classification. We make use of bi-directional transformer based architecture to generate encoded representations from given input followed by task-specific layers for classification. Multi-Task learning (MTL) based framework make use of a different set of tasks in parallel, as a kind of additional regularization, to improve the generalizability of the trained model over individual tasks. We introduced a task-specific auxiliary problem using the k-means clustering algorithm to be trained in parallel with main tasks to reduce the model’s generalization error on the main task. POS-tagging was also used as one of the auxiliary tasks. We also trained multiple benchmark classification datasets in parallel to improve the effectiveness of our bidirectional transformer based network across all the datasets. Our proposed MTL based transformer network im-proved state-of-the-art overall accuracy of Movie Review (MR), AG News, and Stanford Sentiment Treebank (SST-2) corpus by 6%, 1.4%, and 3.3% respectively.
|
|
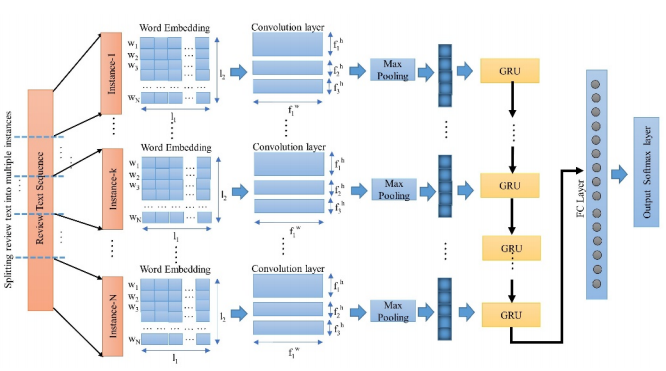
With the increasing influence of online reviews in shaping customer decision-making and purchasing behavior, many unscrupulous businesses have a vested interest in generating and posting deceptive reviews. Deceptive reviews are fictitious reviews written deliberately to sound authentic and deceive the consumers. Traditional deceptive reviews detection methods are based on various handcrafted features, including linguistic and psychological, which characterize the deceptive reviews. However, the proposed deep learning methods have better self-adaptability to extract the desired features implicitly and outperform all traditional methods. We have purposed multiple Deep Neural Network (DNN) based approaches for deceptive reviews detection and have compared the performances of these models on multiple benchmark datasets. Additionally, we have identified a common problem of handling the variable lengths of these reviews. We have purposed two different methods – Multi-Instance Learning and Hierarchical architecture to handle the variable length review texts. Experimental results on multiple benchmark datasets of deceptive reviews have outperformed existing state-of-the-art. We evaluated the performance of the proposed method on other review-related task-like review sentiment detection as well and achieved state-of-the-art accuracies on two benchmark datasets for the same.
|
|
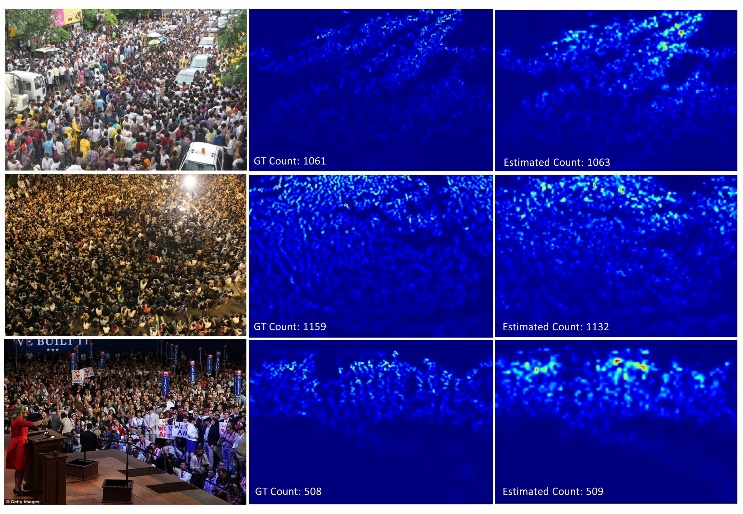
We propose a Multi-Task Learning (MTL) paradigm based deep neural network architecture, called MTCNet (Multi-Task Crowd Network) for crowd density and count estimation. Crowd count estimation is challenging due to the non-uniform scale variations and the arbitrary perspective of an individual image. The proposed model has two related tasks, with Crowd Density Estimation as the main task and Crowd-Count Group Classification as the auxiliary task. The auxiliary task helps in capturing the relevant scale-related information to improve the performance of the main task. The main task model comprises two blocks: VGG-16 front-end for feature extraction and a dilated Convolutional Neural Network for density map generation. The auxiliary task model shares the same front-end as the main task, followed by a CNN classifier. Our proposed network achieves 5.8% and 14.9% lower Mean Absolute Error (MAE) than the state-of-the-art methods on ShanghaiTech dataset without using any data augmentation. Our model also outperforms with 10.5% lower MAE on UCF_CC_50 dataset.
|
|
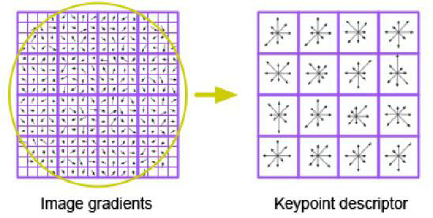
This paper presents a novel approach to exploit the distinctive invariant features in convolutional neural network. The proposed CNN model uses Scale Invariant Feature Transform (SIFT) descriptor instead of the maxpooling layer. Max-pooling layer discards the pose, i.e., translational and rotational relationship between the low-level features, and hence unable to capture the spatial hierarchies between low and high level features. The SIFT descriptor layer captures the orientation and the spatial relationship of the features extracted by convolutional layer. The proposed SIFT Descriptor CNN therefore combines the feature extraction capabilities of CNN model and rotation invariance of SIFT descriptor. Experimental results on the MNIST and fashionMNIST datasets indicates reasonable improvements over conventional methods available in literature.
|
|
This paper proposes a Residual Convolutional Neural Network (ResNet) based on speech features and trained under Focal Loss to recognize emotion in speech. Speech features such as Spectrogram and Mel-frequency Cepstral Coefficients (MFCCs) have shown the ability to characterize emotion better than just plain text. Further Focal Loss, first used in One-Stage Object Detectors, has shown the ability to focus the training process more towards hard-examples and down-weight the loss assigned to well-classified examples, thus preventing the model from being overwhelmed by easily classifiable examples. After experimenting with several Deep Neural Network (DNN) architectures, we propose a ResNet, which takes in Spectrogram or MFCC as input and supervised by Focal Loss, ideal for speech inputs where there exists a large class imbalance. Maintaining continuity with previous work in this area, we have used the University of Southern California’s Interactive Emotional Motion Capture (USC-IEMOCAP) database’s Improvised Topics in this work. This dataset is ideal for our work, as there exists a significant class imbalance among the various emotions. Our best model achieved a 3.4% improvement in overall accuracy and a 2.8% improvement in class accuracy when compared to existing state-of-the-art methods.
|
|
We propose a comprehensive end-to-end pipeline for Twitter hashtags recommendation system including data collection, supervised training setting and zero shot training setting. In the supervised training setting, we have proposed and compared the performance of various deep learning architectures, namely Convolutional Neural Network (CNN), Recurrent Neural Network (RNN) and Transformer Network. However, it is not feasible to collect data for all possible hashtag labels and train a classifier model on them. To overcome this limitation, we propose a Zero Shot Learning (ZSL) paradigm for predicting unseen hashtag labels by learning the relationship between the semantic space of tweets and the embedding space of hashtag labels. We evaluated various state-of-the-art ZSL methods like Convex combination of Semantic Embedding (ConSE), Embarrassingly Simple Zero Shot Learning (ESZSL) and Deep Embedding Model for Zero Shot Learning (DEM-ZSL) for the hashtag recommendation task. We demonstrate the effectiveness and scalability of ZSL methods for the recommendation of unseen hashtags. To the best of our knowledge, this is the first quantitative evaluation of ZSL methods to date for unseen hashtags recommendations from tweet text.
|
|
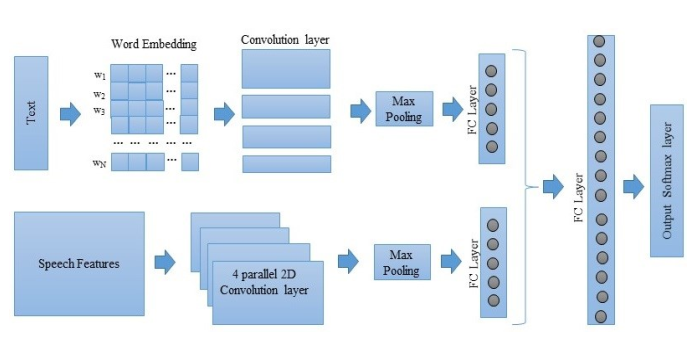
This paper proposes a speech emotion recognition method based on speech features and speech transcriptions (text). Speech features such as Spectrogram and Mel-frequency Cepstral Coefficients (MFCC) help retain emotion-related low-level characteristics in speech whereas text helps capture semantic meaning, both of which help in different aspects of emotion detection. We experimented with several Deep Neural Network (DNN) architectures, which take in different combinations of speech features and text as inputs. The proposed network architectures achieve higher accuracies when compared to state-of-the-art methods on a benchmark dataset. The combined MFCC-Text Convolutional Neural Network (CNN) model proved to be the most accurate in recognizing emotions in IEMOCAP data. We achieved an almost 7% increase in overall accuracy as well as an improvement of 5.6% in average class accuracy when compared to existing state-of-the-art methods.
|
|
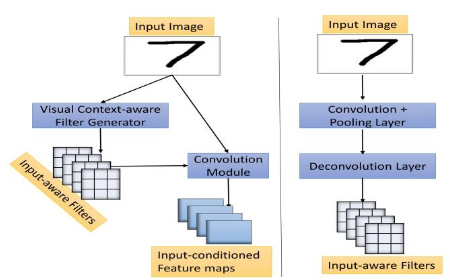
We propose a novel visual context-aware filter generation module which incorporates contextual information present in images into Convolutional Neural Networks (CNNs). In contrast to traditional CNNs, we do not employ the same set of learned convolution filters for all input image instances. Our proposed input-conditioned convolution filters when combined with techniques inspired by Multi-instance learning and max-pooling, results in a transformation-invariant neural network. We investigated the performance of our proposed framework on three MNIST variations, which covers both rotation and scaling variance, and achieved 1.13% error on MNIST-rot-12k, 1.12% error on Half-rotated MNIST and 0.68% error on Scaling MNIST, which is significantly better than the state-of-the-art results. We make use of visualization to further prove the effectiveness of our visual context-aware convolution filters. Our proposed visual context-aware convolution filter generation framework can also serve as a plugin for any CNN based architecture and enhance its modeling capacity.
|
|
|
|

|
The project aimed at building a system for detecting and classifying objects in a video stream into three classes- Pedestrian, Two-Wheeler and Four-Wheeler.
|
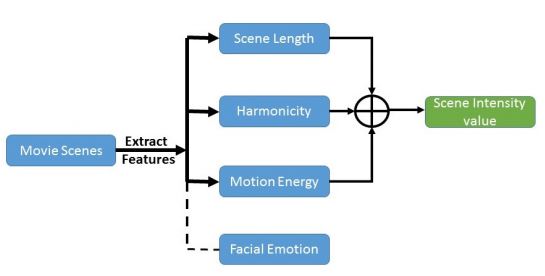
|
The project aims at developing a computational model to estimate scene intensity profile in movies or videos. Scene intensity can be understood as a measure of excitement or activity in a scene.
|

|
The project aimed at exploring various dictionary learning algorithms(k-SVD, MOD, OMP)and implementing sparse representation based application in Image Processing like Image denoising, inpainting, classification, compression etc.
|
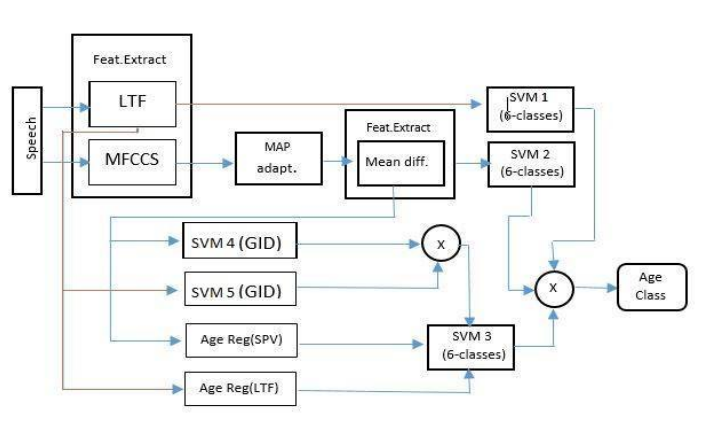
|
The project aimed at building a system for Age and Gender Recognition using speech features.
|
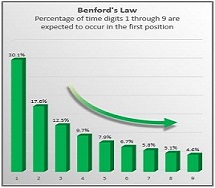
|
Analysed various application of Benford's law in Digital Image Forensics.
|
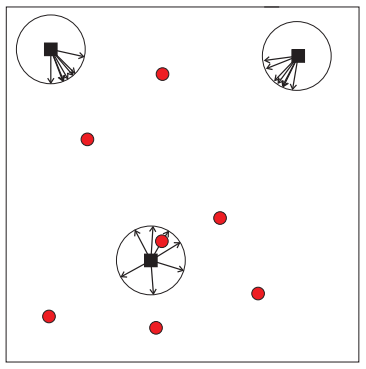
|
The project aimed at developing Maximum depth-based, kNN depth-based, and Hybrid MD-kNN Localizers for ad-hoc Sensor Networks. It have performance improvement in terms of computation time and robustness.
|
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
|
|
|

|
Pyramidal Implementation of Lucas-Kanade-Tomasi (LKT) Feature Tracking Algorithm for 3D Images
|